
Deep Dive in Attention Mechanism: The Backbone of Modern NLP
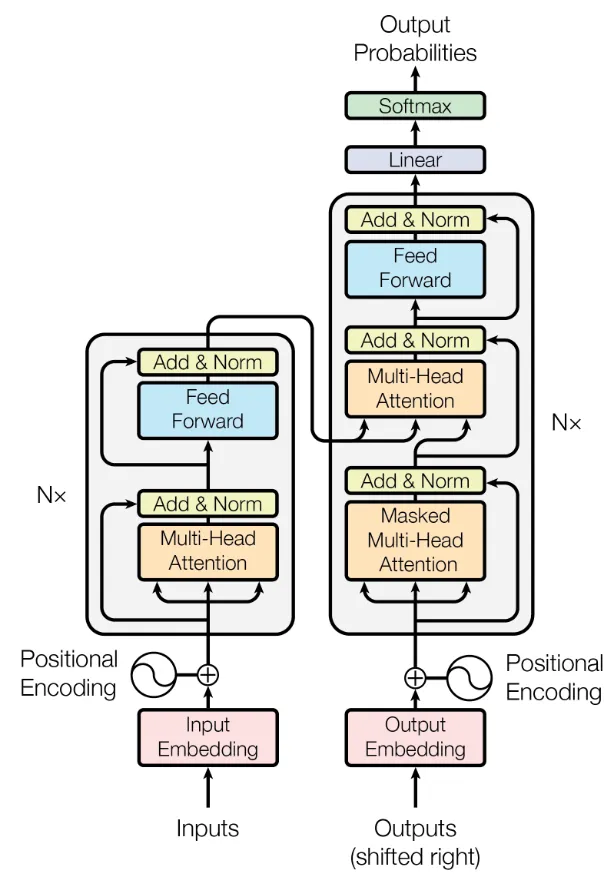
Attention mechanisms have revolutionized the field of natural language processing (NLP) and have become the backbone of state-of-the-art models like BERT, GPT, and other transformer-based architectures. But what exactly is attention, and why has it been so transformative? In this article, we'll take a deep dive into the attention mechanism, exploring its origins, how it works, and why it's so effective.
What is the Attention Mechanism?
At its core, attention is a technique that enhances the ability of neural networks to focus on relevant parts of input data while processing it. In the context of NLP, attention allows a model to weigh the importance of different words in a sentence when generating a response or making a prediction.
Think of attention as similar to how humans process language. When reading a sentence, we don't assign equal importance to every word. Instead, we focus more on certain words that provide the contextual meaning. For example, in the sentence "The cat, which has a red collar, is sleeping on the mat," if someone asks you what the cat is doing, you'll pay more attention to "sleeping" and "mat" than to "red" and "collar" when formulating your response.
The attention mechanism formalizes this intuitive concept, allowing neural networks to selectively focus on specific parts of input sequences when producing outputs.
A Brief History of Attention Mechanisms
The concept of attention in neural networks wasn't born overnight. Here's a brief timeline of its evolution:
-
2014: Bahdanau et al. introduced the first widely recognized attention mechanism in their paper "Neural Machine Translation by Jointly Learning to Align and Translate." This was a groundbreaking advancement for machine translation, addressing limitations of fixed-length context vectors in sequence-to-sequence models.
-
2015: Luong et al. refined attention with their "Effective Approaches to Attention-based Neural Machine Translation," introducing global and local attention variants.
-
2017: The landmark paper "Attention Is All You Need" by Vaswani et al. introduced the Transformer architecture, which relies solely on attention mechanisms without using recurrent or convolutional layers. This paper revolutionized NLP and established attention as the dominant paradigm.
-
2018-Present: Attention-based models like BERT, GPT, T5, and others have continuously pushed the state-of-the-art in various NLP tasks, cementing attention as a fundamental component of modern deep learning systems.
How Attention Works
Let's demystify the attention mechanism by breaking it down into its core components:
The Intuition
When processing a sequence (like a sentence), for each element (like a word), attention calculates how much focus should be placed on every other element when producing the output for the current element. This creates a weighted sum where more important elements contribute more significantly to the result.
Key Mathematical Components
Attention typically involves three main components:
- Queries (Q): What we're looking for
- Keys (K): What we're comparing against
- Values (V): What we're extracting information from
The process works like this:
- For each position, compute a compatibility score between its query and all keys
- Convert these scores to weights using softmax (ensuring they sum to 1)
- Use these weights to create a weighted sum of the values
Scaled Dot-Product Attention
The most common form of attention used in Transformers is scaled dot-product attention, defined as:
Attention(Q, K, V) = softmax(QK^T / √d_k) VAttention(Q, K, V) = softmax(QK^T / √d_k) VWhere:
- Q is the query matrix
- K is the key matrix
- V is the value matrix
- d_k is the dimension of the keys (used for scaling)
The scaling factor (√d_k) prevents the dot products from growing too large in magnitude, which could push the softmax function into regions with extremely small gradients.
An Intuitive Example
Let's consider a simple example to better understand attention. Imagine we're translating the English sentence "The cat chased the mouse" to French.
When the translation model is generating the French word for "chased," it needs to focus primarily on the word "chased" in the English sentence, but also maintain some awareness of "cat" (the subject) and "mouse" (the object). The attention mechanism allows the model to assign appropriate weights:
- "The" → 0.05 (low attention)
- "cat" → 0.25 (moderate attention, as it's the subject)
- "chased" → 0.50 (high attention, as it's the word being translated)
- "the" → 0.05 (low attention)
- "mouse" → 0.15 (some attention, as it's the object)
These weights help the model focus on relevant context when generating each word in the translation.
Implementing Attention in Python
Let's implement a simple version of the scaled dot-product attention mechanism in pure Python using NumPy:
import numpy as np
def scaled_dot_product_attention(queries, keys, values, mask=None):
"""
Calculate the attention weights using scaled dot-product attention.
Args:
queries: Query tensor of shape (..., seq_len_q, depth)
keys: Key tensor of shape (..., seq_len_k, depth)
values: Value tensor of shape (..., seq_len_k, depth_v)
mask: Optional mask tensor of shape (..., seq_len_q, seq_len_k)
Returns:
output: Weighted sum of values
attention_weights: Attention weights
"""
# Calculate dot product of queries and keys
matmul_qk = np.matmul(queries, np.transpose(keys, (0, 2, 1)))
# Scale matmul_qk
depth = keys.shape[-1]
scaled_attention_logits = matmul_qk / np.sqrt(depth)
# Apply mask (if provided)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# Apply softmax to get attention weights
attention_weights = np.exp(scaled_attention_logits) / np.sum(
np.exp(scaled_attention_logits), axis=-1, keepdims=True)
# Calculate weighted sum of values
output = np.matmul(attention_weights, values)
return output, attention_weights
# Example usage
def create_example_inputs():
batch_size = 2
seq_len_q = 4 # query sequence length
seq_len_k = 6 # key sequence length (can differ from query length)
depth = 8 # dimension of the query and key vectors
depth_v = 10 # dimension of the value vectors
queries = np.random.random((batch_size, seq_len_q, depth))
keys = np.random.random((batch_size, seq_len_k, depth))
values = np.random.random((batch_size, seq_len_k, depth_v))
return queries, keys, values
# Run the example
queries, keys, values = create_example_inputs()
output, attention_weights = scaled_dot_product_attention(queries, keys, values)
print(f"Output shape: {output.shape}")
print(f"Attention weights shape: {attention_weights.shape}")
# Visualize attention weights for first example in batch
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
plt.matshow(attention_weights[0], cmap='viridis')
plt.title('Attention weights')
plt.xlabel('Key positions')
plt.ylabel('Query positions')
plt.colorbar()
plt.savefig('attention_weights.png')import numpy as np
def scaled_dot_product_attention(queries, keys, values, mask=None):
"""
Calculate the attention weights using scaled dot-product attention.
Args:
queries: Query tensor of shape (..., seq_len_q, depth)
keys: Key tensor of shape (..., seq_len_k, depth)
values: Value tensor of shape (..., seq_len_k, depth_v)
mask: Optional mask tensor of shape (..., seq_len_q, seq_len_k)
Returns:
output: Weighted sum of values
attention_weights: Attention weights
"""
# Calculate dot product of queries and keys
matmul_qk = np.matmul(queries, np.transpose(keys, (0, 2, 1)))
# Scale matmul_qk
depth = keys.shape[-1]
scaled_attention_logits = matmul_qk / np.sqrt(depth)
# Apply mask (if provided)
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# Apply softmax to get attention weights
attention_weights = np.exp(scaled_attention_logits) / np.sum(
np.exp(scaled_attention_logits), axis=-1, keepdims=True)
# Calculate weighted sum of values
output = np.matmul(attention_weights, values)
return output, attention_weights
# Example usage
def create_example_inputs():
batch_size = 2
seq_len_q = 4 # query sequence length
seq_len_k = 6 # key sequence length (can differ from query length)
depth = 8 # dimension of the query and key vectors
depth_v = 10 # dimension of the value vectors
queries = np.random.random((batch_size, seq_len_q, depth))
keys = np.random.random((batch_size, seq_len_k, depth))
values = np.random.random((batch_size, seq_len_k, depth_v))
return queries, keys, values
# Run the example
queries, keys, values = create_example_inputs()
output, attention_weights = scaled_dot_product_attention(queries, keys, values)
print(f"Output shape: {output.shape}")
print(f"Attention weights shape: {attention_weights.shape}")
# Visualize attention weights for first example in batch
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
plt.matshow(attention_weights[0], cmap='viridis')
plt.title('Attention weights')
plt.xlabel('Key positions')
plt.ylabel('Query positions')
plt.colorbar()
plt.savefig('attention_weights.png')This implementation shows the basic mechanics of scaled dot-product attention. In real-world scenarios, you'd typically use specialized libraries like TensorFlow or PyTorch, which optimize these operations for efficiency.
Multi-Head Attention
In practice, Transformers use multi-head attention, which allows the model to focus on information from different representation subspaces at different positions:
def multi_head_attention(queries, keys, values, num_heads=8, mask=None):
"""
Multi-head attention allows the model to jointly attend to
information from different representation subspaces.
Args:
queries, keys, values: Input tensors
num_heads: Number of attention heads
mask: Optional mask
Returns:
Output tensor and attention weights
"""
batch_size = queries.shape[0]
depth = queries.shape[-1]
depth_per_head = depth // num_heads
# Linear projections
q = np.random.random((batch_size, queries.shape[1], depth)) # In practice, this would be a learned projection
k = np.random.random((batch_size, keys.shape[1], depth))
v = np.random.random((batch_size, values.shape[1], depth))
# Split heads
q = np.reshape(q, (batch_size, -1, num_heads, depth_per_head))
q = np.transpose(q, (0, 2, 1, 3)) # (batch_size, num_heads, seq_len, depth_per_head)
k = np.reshape(k, (batch_size, -1, num_heads, depth_per_head))
k = np.transpose(k, (0, 2, 1, 3))
v = np.reshape(v, (batch_size, -1, num_heads, depth_per_head))
v = np.transpose(v, (0, 2, 1, 3))
# Apply attention to each head
outputs = []
attentions = []
for h in range(num_heads):
output, attention = scaled_dot_product_attention(
q[:, h, :, :], k[:, h, :, :], v[:, h, :, :], mask)
outputs.append(output)
attentions.append(attention)
# Concatenate and apply final linear projection
concat_output = np.concatenate([np.expand_dims(o, axis=1) for o in outputs], axis=1)
concat_output = np.transpose(concat_output, (0, 2, 1, 3))
concat_output = np.reshape(concat_output, (batch_size, -1, depth))
# Final linear projection would be applied here in practice
return concat_output, attentionsdef multi_head_attention(queries, keys, values, num_heads=8, mask=None):
"""
Multi-head attention allows the model to jointly attend to
information from different representation subspaces.
Args:
queries, keys, values: Input tensors
num_heads: Number of attention heads
mask: Optional mask
Returns:
Output tensor and attention weights
"""
batch_size = queries.shape[0]
depth = queries.shape[-1]
depth_per_head = depth // num_heads
# Linear projections
q = np.random.random((batch_size, queries.shape[1], depth)) # In practice, this would be a learned projection
k = np.random.random((batch_size, keys.shape[1], depth))
v = np.random.random((batch_size, values.shape[1], depth))
# Split heads
q = np.reshape(q, (batch_size, -1, num_heads, depth_per_head))
q = np.transpose(q, (0, 2, 1, 3)) # (batch_size, num_heads, seq_len, depth_per_head)
k = np.reshape(k, (batch_size, -1, num_heads, depth_per_head))
k = np.transpose(k, (0, 2, 1, 3))
v = np.reshape(v, (batch_size, -1, num_heads, depth_per_head))
v = np.transpose(v, (0, 2, 1, 3))
# Apply attention to each head
outputs = []
attentions = []
for h in range(num_heads):
output, attention = scaled_dot_product_attention(
q[:, h, :, :], k[:, h, :, :], v[:, h, :, :], mask)
outputs.append(output)
attentions.append(attention)
# Concatenate and apply final linear projection
concat_output = np.concatenate([np.expand_dims(o, axis=1) for o in outputs], axis=1)
concat_output = np.transpose(concat_output, (0, 2, 1, 3))
concat_output = np.reshape(concat_output, (batch_size, -1, depth))
# Final linear projection would be applied here in practice
return concat_output, attentionsWhy Attention Works So Well
Attention mechanisms have been revolutionary in NLP for several key reasons:
1. Long-range dependencies
Traditional RNNs and LSTMs struggle with long sequences because information from early tokens must pass through many processing steps to influence later tokens. Attention creates direct connections between positions, allowing the model to consider relationships between words regardless of their distance in the sequence.
2. Parallelization
RNNs process sequences sequentially, making training slow for long sequences. Attention-based models like Transformers can process all tokens in parallel during training, dramatically speeding up the process.
3. Interpretability
Attention weights provide a degree of interpretability that's often lacking in deep neural networks. By examining attention patterns, we can gain insights into which parts of the input the model focuses on when making predictions.
4. Flexibility
Attention can be applied to a wide range of sequence types beyond text, including images, audio, and time-series data, making it a versatile building block for various applications.
5. Context-aware representations
Attention helps create context-aware representations of tokens, where each token's representation is influenced by other relevant tokens in the sequence. This is crucial for handling ambiguity in language.
Advanced Applications of Attention
Attention has expanded far beyond its original applications:
-
Self-attention: Where queries, keys, and values all come from the same source, allowing a sequence to attend to itself.
-
Cross-attention: Where queries come from one sequence, while keys and values come from another, useful in tasks like machine translation.
-
Sparse attention patterns: Models like Longformer and Big Bird use sparse attention patterns to efficiently handle very long sequences.
-
Local attention: Models like Performer and Linformer approximate the attention calculation to reduce computational complexity.
-
Vision transformers: Extending attention to computer vision tasks by treating images as sequences of patches.
Conclusion
Attention mechanisms have fundamentally changed how we approach sequence modeling problems. By allowing models to focus on relevant parts of the input when generating each part of the output, attention has enabled significant advances in machine translation, text summarization, question answering, and many other NLP tasks.
The introduction of the Transformer architecture, which relies entirely on attention mechanisms, marked a paradigm shift in NLP, leading to models like BERT and GPT that have achieved remarkable results across a wide range of tasks.
As research continues to advance, we're seeing attention mechanisms applied to increasingly diverse domains, from computer vision to reinforcement learning, suggesting that this powerful concept will remain central to deep learning for years to come.
Whether you're building a chatbot, a translation system, or any other application that processes sequential data, understanding attention mechanisms is now an essential skill for machine learning practitioners. I hope this article has given you a solid foundation in both the theory and practical implementation of this revolutionary concept.
About Md. Mobin Chowdhury
Md. Mobin Chowdhury is an undergraduate Physics student at University of Dhaka, combining theoretical physics research with self-taught expertise in AI and quantum computing.
Comments
Do you have a problem, want to share feedback, or discuss further ideas? Feel free to leave a comment here! Please stick to English. This comment thread directly maps to a discussion on GitHub, so you can also comment there if you prefer.
Instead of authenticating the giscus application, you can also comment directly on GitHub.
Related Articles
React Native vs Flutter: The Ultimate Showdown for Cross-Platform Dominance in 2023
This comprehensive comparison dives deep into React Native and Flutter, the two titans of cross-platform mobile development. Explore their architectures, performance metrics, learning curves, and business advantages. Whether you're a startup founder deciding on your tech stack, a developer contemplating which framework to master, or a project manager planning your next mobile app, this analysis will help you make an informed decision that aligns with your specific needs and goals.
Job and AI: My Thoughts
An optimistic perspective on how AI, particularly large language models, is reshaping the job market for computer science professionals. This article explores the opportunities AI creates, its limitations, and the challenges faced by junior and copycat developers.